If the basic technical ideas behind Deep Learning are around for decades, why are they taking off today ?
In this post I will go over the main drivers behind Deep Learning, which will help you to spot the best opportunities to apply these tools.
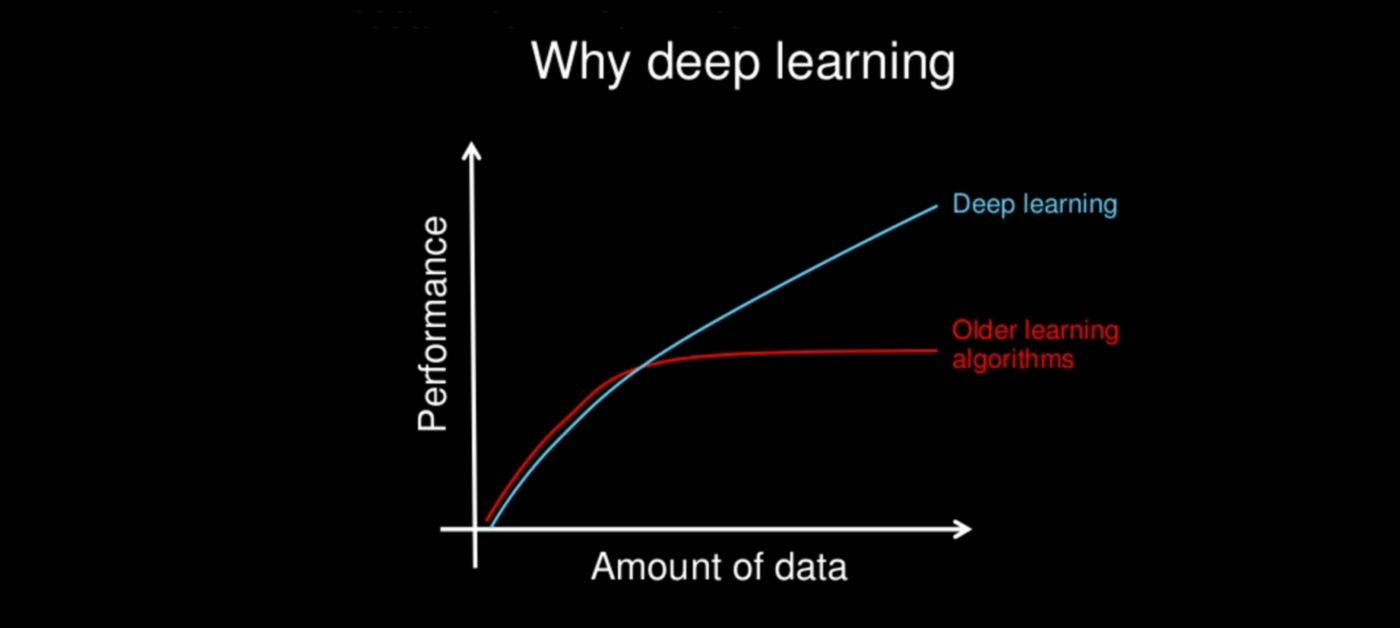
The best thing to answer this question would be to show and explain you the picture below.

At the vertical axes of the diagram you can see the performance of an algorithm (e.g. it’s prediction accuracy) and at the horizontal axes you can see the amount of data it has been given.
You can also see that the performance of traditional learning algorithms (logistic Regression, SVM’s etc.) increases at the beginning with an increase of the amount of data but that it plateaus at a certain level and stops improving it’s performance.
The thing is that we have accumulated huge amounts of data over the last decades where our traditional learning algorithms can’t take advantage of, which is where Deep Learning comes into play.
Large Neural Networks (e.g. Deep Learning) are getting better and better the more data you put into them. Andrew NG, a leading AI scientist, said that the three main forces which improve Neural Networks are:
- Data
- Computation
- Algorithms
Getting a better accuracy with deep learning algorithms is either due to a better Neural Network, more computational power or huge amounts of data. Eventually you will reach a certain point where you don’t have enough data left or where you cant improve the algorithm anymore because it then will take too much time to train.
If you don’t have enough data it doesn’t really matter if you use deep learning- or traditional algorithms but it matters how well you have adjusted your model to it’s current prediction goal. So if you don’t have big amounts of data it is often up to your skills to score a high accuracy.
The recent breakthroughs in the development of algorithms are mostly due to making them run much faster than before, which makes it possible to use more and more data. For an example, a big advancement came from switching from a Sigmoid function (left picture) to a rectified-Linear-Unit function (right picture).
One of the problems of using the Sigmoid function within deep learning was that at the points, which are marked with an arrow, the slope of the function (the gradients) are nearly zero which causes that the parameters change very slowly and therefore learning becomes really slow. In using RELU as activation function, the gradients are equal to one for all positive values of input and so on the gradients are less likely to decrease to zero.

The other reasons that fast computation is important is because the process of training neural networks is very iterative.
You have an idea for a neural network architecture, then you code your idea and then you run an experiment which tells you how well your model does. Then you look back at the details of your neural network, change something and let it run again, therefore fast computation makes you much faster in finding the right solution. The illustration below shows this concept very good.


Great post! Hope to read more soon…
LikeLike